#PropensityScoreMatch #Python #Statistics
最近開始整理之前的研究檔案,其中一個retrospective cohort study所收集到的實驗與對照組人數落差太大,對照組是試驗組的10倍以上。為了減少研究的落差,可以採用Propensity score matching的方式。
以下有兩個方法透過python來處理:
## method1:
參考:matched pairs in Python (Propensity score matching)
### code:
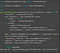
from sklearn.preprocessing import StandardScalerfrom sklearn.neighbors import NearestNeighbors
def get_matching_pairs(treated_df, non_treated_df, scaler=True):
treated_x = treated_df.values
non_treated_x = non_treated_df.values
if scaler == True:
scaler = StandardScaler()
if scaler:
scaler.fit(treated_x)
treated_x = scaler.transform(treated_x)
non_treated_x = scaler.transform(non_treated_x)
nbrs= NearestNeighbors(n_neighbors=1,algorithm=’ball_tree’).fit(non_treated_x)
distances, indices = nbrs.kneighbors(treated_x)
indices = indices.reshape(indices.shape[0])
matched = non_treated_df.iloc[indices]
return matched
matched_df = get_matching_pairs(treated_df, non_treated_df)

### 說明與思考
這段程式碼使用sklearn的scalar先把數值標準化,在透過NearestNeighbors的方式,找到最接近的個案!可以直接拿來產出兩組,在進行後面的研究流程。
## method 2
參考:heart-propensity-score-matching.pdf
# python
model = ‘treated ~ age + male +edu’ propensity = smf.logit(formula=model, data = df).fit() propensity.summary()
### 思考
1. 這個方式,透過logit regression,產出一個針對’group’的預測數值。
2. 可以直接這個數值當作一個控制變因來使用!
## See Also :









沒有留言:
張貼留言